Beyond Code Comparison: Mito's Functional Evaluation Approach to AI Testing
Evaluating the performance and capabilities of Large Language Models (LLMs) is a crucial process, and while there is no single unified approach, patterns can be adapted for specific use cases. For general-purpose models, benchmarks like MMLU are popular, but for domain- and task-specific models, more focused evaluations often provide greater benefit. When it comes to AI-generated code for tasks like data analysis, traditional evaluation methods often fall short by focusing on superficial code similarity. Mito embraces a different paradigm, centering its evaluation on what truly matters: the functional results of the generated code.
The Problem with Traditional Code Evaluation
Traditional code evaluation frequently falls into the trap of expecting AI-generated code to be a carbon copy of a human-written reference solution. This “string matching trap” overlooks the fundamental truth that there are countless valid ways to write code that achieves the same outcome. Differences in stylistic choices like variable names, code formatting, or even the algorithmic approach taken do not necessarily impact the code’s functionality. Insisting on exact string matches can stifle AI creativity and miss equally valid, albeit structurally different, solutions.
Mito’s Execution-Based Evaluation
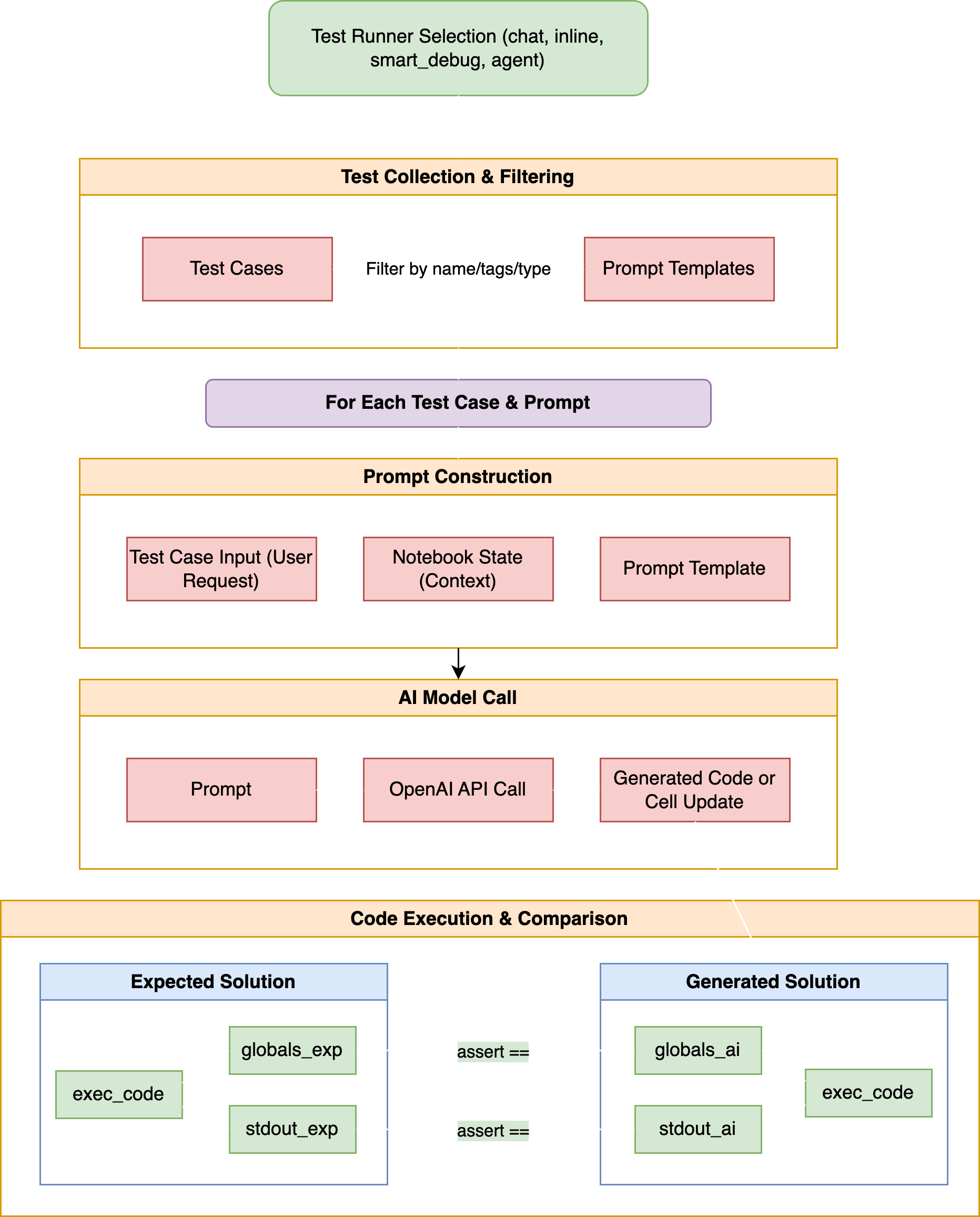
Instead of getting bogged down in syntactic comparisons, Mito’s evaluation system focuses on what code actually does: it executes both the AI-generated code and a reference solution within isolated environments and then compares their effects.
This execution-based approach assesses two critical dimensions:
1. Global Variable State Comparison
After the execution of both code snippets, Mito intelligently compares the variables that were created or modified. This comparison is not a simple object identity check but understands the nuances of different data types:
- For basic data types like integers and strings, a direct equality check is performed.
- For pandas DataFrames, DataFrame-specific equality methods are used to compare the data content, irrespective of object identity.
- NumPy arrays are compared using functions that correctly handle special values like NaN.
- For custom objects, their defined equality behavior is respected.
This sophisticated comparison means that if two code solutions generate a DataFrame with the same data, they will pass this test, even if their underlying implementations (e.g., using df.query() versus boolean indexing) differ.
2. Output Comparison
Beyond variable state, Mito also captures and compares the standard output (anything printed to the console) from both executions. This ensures that any visualization or reporting functionality works identically.
summary = df.groupby('region').agg({
'revenue': 'sum',
'order_value': 'mean'
}).reset_index()
Real-World Example: The Power of Functional Equivalence
Consider this example:
User request: “Create a DataFrame summarizing sales by region, showing total revenue and mean order value.”
Reference solution:
summary = df.groupby('region').agg({
'revenue': 'sum',
'order_value': 'mean'
}).reset_index()
AI-generated solution:
region_groups = df.groupby('region')
total_revenue = region_groups['revenue'].sum()
avg_order = region_groups['order_value'].mean()
summary = pd.DataFrame({
'region': total_revenue.index,
'revenue': total_revenue.values,
'order_value': avg_order.values
})
Under traditional string comparison, these would be considered completely different. But Mito’s execution-based evaluation recognizes that both produce functionally identical summary DataFrames with the same data.
Why This Approach Matters
This execution-focused evaluation brings several critical advantages:
- Embraces AI Creativity: It allows AI to find novel solutions rather than forcing it to mimic a specific style.
- Focuses on User Intent: What matters is whether the AI satisfied the user’s request, not how it constructed the solution.
- Handles Edge Cases Naturally: The comparison automatically handles complexities like floating-point precision differences and object equivalence.
- Mirrors Real-World Usage: Users care about results, not code aesthetics—this approach aligns evaluation with actual success criteria.
- Enables Objective Measurement: Success is binary and objectively determinable: either the code produces the correct output and variable state, or it doesn’t.
Implementing Your Own Execution-Based Evaluation
The core of Mito’s approach can be adapted by others building AI coding tools:
- Execute reference and AI code in isolated environments
- Capture the resulting variable state and outputs
- Compare them using type-appropriate equality checks
- Base success on functional equivalence rather than code similarity
This shift from syntactic comparison to functional evaluation represents a fundamental advancement in how we should evaluate AI-generated code—focusing on what matters most: whether the code does what the user asked for.
By focusing on execution results rather than implementation details, Mito has created an evaluation framework that truly measures what matters for users—reliable results over superficial code similarity.
